You might have encountered a situation where you need to “digitize” stacks of text documents such as contract agreements and written notes. Although it is fairly easy to use a desktop scanner to convert the documents into the digital format but have you wonder if the output from the scanner is processing ready? The free Windows-based Optical Character Recognition (OCR) application – FreeOCR is the helpful tool which allow you to convert a scanned document into electronic files containing readable text.
In contrast to the scanned image, the files generated by FreeOCR are processable by word processors to support functions such as text search and editing. FreeOCR is a relatively small application with simple GUI to scan a document and convert it into processing ready text files. FreeOCR is a great alternative if you do not wish to install the huge companion software that usually bundled together with the scanner.
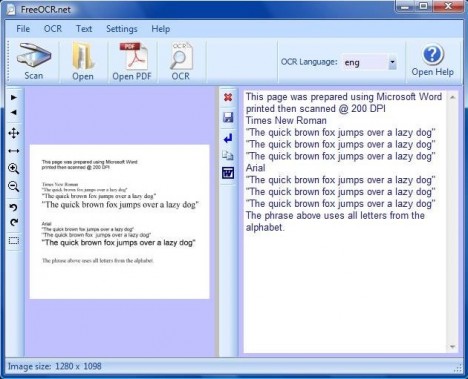
Here are the features of FreeOCR:
- Scan a document from any Twain or Wia compatible scanner using scanning resolution of 300dpi
- Supports most image files including multipage TIFF files
- FreeOCR utilizes the open source Tesseract OCR engine which enables it to extract and recognize the text precisely. Tesseract OCR engine is currently maintained by Google and it is one of the most accurate open source OCR engines available today.
- OCR PDF rendering without any 3rd party software installed e.g. Ghostscript or Adobe Acrobat
- Supported languages include Portuguese (Brazilian), Fraktur (Old German), Dutch, Spanish, German, Italian, Vietnamese, French and English.
- Available for Windows 2000, 2003, XP, Vista, Win 7.
FreeOCR is distributed under the Apache V2.0 license and it is a freeware including free commercial use. FreeOCR is available free download at http://www.paperfile.net/freeocr.exe.
 Tip and Trick
Tip and Trick
- How To Download HBO Shows On iPhone, iPad Through Apple TV App
- Windows 10 Insider Preview Build 19025 (20H1) for PC Official Available for Insiders in Fast Ring – Here’s What’s News, Fixes, and Enhancement Changelog
- Kaspersky Total Security 2020 Free Download With License Serial Key
- Steganos Privacy Suite 19 Free Download With Genuine License Key
- Zemana AntiMalware Premium Free Download For Limited Time